백엔드 개발자가 알아야 할 데이터 종류와 시스템 기초 지식
동일 버전 : https://wikidocs.net/book/18832
이제 개발을 시작하는 사람을 위한 글입니다.
1. 서문
디지털 정보의 세계는 0과 1이라는 비트의 조합으로 이루어져 있지만, 인간이 이해할 수 있는 지식으로 변환되기 위해서는 다층적인 추상화 과정이 필요하다. 데이터가 저장 매체에 기록되는 가장 근본적인 파일 시스템(File System)에서부터, 저장 공간의 효율성을 극대화하는 압축 알고리즘(Compression), 데이터를 구조화하여 표현하는 파일 포맷(File Format), 그리고 데이터의 효율적인 검색과 관리를 담당하는 데이터베이스 관리 시스템(DBMS)에 이르기까지 데이터 지속성(Persistence)을 구성하는 전체 기술 스택을 대략적으로 알아본다.
만능 원툴은 존재하지 않고 모든 것에는 트레이드오프(Trade-off)가 있다. 초급 백엔드 개발가 선택의 기로에 섰을 때 도움이 되는 문서가 되길 바란다.
AI 를 이용해 조사하고 글을 다듬었음을 밝힌다.
2. 파일 구조 및 데이터 직렬화
파일은 크게 문자 기반의 사람이 읽을 수 있는 텍스트 형식과 바이트 단위의 바이너리 형식(format)으로 나눌 수 있다. 물론 근본적으로 보면 바이너리가 기반이고, 사람이 읽을 수 있도록 표준을 정하고 처리하는 것이 텍스트 형식이다.
직렬화(serialization)는 데이터를 저장하거나 네트워크로 전송하기 위해서는 메모리 상의 객체를 바이트 스트림으로 변환하는 것이다. 이 과정에서 선택되는 파일 형식은 시스템의 성능, 가독성, 그리고 상호운용성을 결정짓는 핵심 요소가 된다.
텍스트 기반 형식은 인간이 특수한 도구 없이도 내용을 읽고 수정할 수 있다는 장점이 있어 구성 파일이나 데이터 교환용으로 널리 사용된다. 그러나 파싱 비용이 높고 저장 공간 효율이 낮다는 단점이 있다.
2.1.1 비정형 및 반정형 텍스트
-
Plain Text (.txt): 가장 단순한 형태의 데이터 저장 방식이다. 구조에 대한 메타데이터가 전혀 포함되지 않으며, 인코딩(ASCII, UTF-8 등) 외에는 별다른 규칙이 없다. 로그 파일이나 간단한 메모 저장용으로 사용되지만, 데이터의 의미를 해석하기 위해서는 외부의 로직이 전적으로 필요하다. 이것을 **선택하는 이유는 순전히 사람이 바로 읽기 위함이다. **
-
CSV (Comma-Separated Values) 및 TSV: 엑셀과 같은 스프레드시트 데이터 교환의 사실상 표준이다. 쉼표(,)나 탭(\t)으로 열을 구분하고 줄바꿈으로 행을 구분한다. 구현이 매우 간단하고 인간이 읽기 쉽다는 장점이 있지만, 데이터 타입(숫자와 문자열 구분 등)에 대한 명시적 정보가 부족하고, 쉼표가 포함된 데이터를 처리하기 위한 이스케이프 처리가 표준화되지 않아 파싱 오류가 발생하기 쉽다. Plain Text는 형식이 없다. 컴퓨터는 구조화된 데이터를 반복처리하는데 효율적이다. CSV는 구조를 정의해서 일정한 형식의 데이터를 처리하기 쉽게 정의한 것이다.
-
Netstrings: 텍스트 데이터의 경계를 명확히 하기 위해 고안된 형식으로, 문자열의 길이를 데이터 앞에 명시한다(예: 3:cat,). 이는 구분자(delimiter) 방식의 문제점인 충돌을 방지하고 파싱을 단순화하지만, JSON이나 XML에 비해 널리 사용되지는 않는다.
2.1.2 계층적 데이터 형식
계층적 데이터 형식은 앞서 소개한 파일 형식에서 파싱 할 때 쉽게 오류가 발생하는 방지 할 수 있다. 직렬화를 위해 명확한 파싱 규칙을 정의한다.
텍스트 기반의 계층적 데이터를 정의한 파일 포맷은 사람이 읽을 수 있는 것(쉬움)과 데이터를 처리하는 코드를 쉽게 만들 수 있는 것을 목표로 했다.
기술 세계에서 좋은 것보다 쉬운 것이 '사실상 표준’으로 선택되는 경향이 있다.
-
XML (eXtensible Markup Language): 1990년대 후반과 2000년대 초반 엔터프라이즈 시스템을 지배했던 형식이다. 태그(Tag)를 사용하여 데이터의 계층 구조를 명확히 표현하며, 스키마(XSD)를 통해 데이터의 유효성을 엄격하게 검증할 수 있다. 그러나 닫는 태그의 중복으로 인해 파일 크기가 커지고, DOM 또는 SAX 파서를 통한 처리 비용이 높아 현대의 웹 API에서는 JSON에 자리를 내주었다. 처리 비용에는 학습비용도 포함된다. XML 규칙을 학습하고, 파서를 학습하고 나서 실제 코드를 짤 때, 코드 양이 많아서 진저리 나기도 한다. 자동화를 위해 개발된 구조긴한데 자동화를 위한 개발 비용이 비싸다.
-
JSON (JavaScript Object Notation): 자바스크립트 객체 문법을 따르는 경량의 데이터 교환 형식이다. 키-값 쌍(Key-Value Pair)으로 이루어져 있으며, 인간이 읽기 쉽고 기계가 파싱하기에도 XML보다 가볍다. 현대 웹 API와 NoSQL 데이터베이스(MongoDB 등)의 표준 문서 형식으로 자리 잡았다. 다만, 주석을 지원하지 않고 날짜(Date)와 같은 복잡한 타입을 기본 지원하지 않는 한계가 있다. 후에 확장 형식들이 등장하여 이런 점을 보완하였으나 널리 받아들여지진 않았다.
-
YAML (YAML Ain’t Markup Language): 주로 구성 파일(Configuration) 작성에 사용된다. 중괄호나 태그 대신 들여쓰기(Indentation)를 통해 계층 구조를 표현하므로 가독성이 매우 뛰어나다. 앵커(Anchor) 기능을 통해 중복 데이터를 참조할 수 있는 기능이 있어 복잡한 설정 파일 작성 시 유용하다. 쿠버네티스(Kubernetes)나 앤서블(Ansible) 등에서 널리 사용된다.
-
HTML (HyperText Markup Language): 웹 페이지의 구조를 정의하는 마크업 언어입니다. 웹 브라우저가 이해하고 표시하기 위한 텍스트 파일이다.
-
마크다운 (Markdown, .md): 간단한 기호를 사용해 서식을 지정하는 마크업 언어. 블로그, 문서 작성 등에 사용된다.
-
.ini, .cfg (설정 파일): 프로그램 설정 값을 저장하는 텍스트 파일로, 섹션과 키-값 쌍으로 구성된다.
텍스트 기반 파일을 처리 할 때는 특수 문자 처리 규칙, 인코딩 불일치 문제들이 발생 할 수 있다.
따라서 프로그래밍 언어, 파일 포맷 별 특수 문자 처리 규칙, 인코딩 불일치 해결 방법 등을 숙지해야 한다.
2.2 이진 직렬화 형식 (Binary Serialization)
이진 형식은 데이터를 바이트 단위로 최적화하여 저장하므로 텍스트 형식에 비해 크기가 훨씬 작고 파싱 속도가 빠르다. 시스템 간 통신(RPC)이나 대용량 데이터 저장에 필수적이다.
프로그래밍 언어에서는 파일 이나 스트림 기반의 데이터 저장 함수를 제공한다.
처음 파일을 다루는 코드를 접하면 특정한 포맷이 아닌, 바이트 배열을 파일에 순차적으로 쓰고 읽는 코드를 작성할 것이다.
예를 들어 [이름, 나이, 주소] 배열을 저장하고 읽는 코드를 작성했다.
그런데 [이름,나이,성별,주소]로 변경하면 잘 준비가 되어 있지 않다면 이전에 저장했던 파일을 이용하는데 어려움이 생길 것이다.
그렇기 때문에 데이터 구조가 변경 돼도 대응 할 수 있는 파일 포맷 들이 개발되었다.
목적에 맞는 파일 포맷을 선택해야 하며, 몇가지 포맷을 소개하니 실전에서는 이것을 참고하여 관련 된것을 찾아서 확장하길 바란다.
2.2.1 스키마 기반 직렬화
스키마 기반 직렬화는 데이터 구조를 정의 하는 방식을 제공하는 라이브러리 들이다.
-
Protocol Buffers (Protobuf): 구글이 개발한 직렬화 형식이다. .proto 파일을 통해 데이터 스키마를 미리 정의하고, 이를 기반으로 각 언어에 맞는 코드를 생성한다. 데이터에는 필드 이름이 포함되지 않고 필드 ID만 포함되므로 크기가 매우 작다. gRPC 통신의 기본 포맷으로 사용되며, 스키마가 있어야만 데이터를 해독할 수 있다. gRPC 프로토콜과 사용되며 유명해졌다. Protobuf
-
Apache Thrift: 페이스북이 개발한 프레임워크로, Protobuf와 유사하게 IDL(Interface Definition Language)을 사용하여 서비스를 정의한다. 다양한 프로그래밍 언어를 지원하며, 하둡 생태계 및 대규모 분산 시스템의 RPC 통신에 널리 사용된다. Apache Thrift
-
Apache Avro: 하둡 프로젝트에서 데이터 직렬화를 위해 개발되었다. 스키마를 JSON 형식으로 정의하며, 데이터와 스키마를 함께 저장하거나 스키마 레지스트리를 통해 관리한다. 특히 스키마 진화(Schema Evolution)를 강력하게 지원하여, 필드가 추가되거나 삭제되어도 구버전과 신버전 간 호환성을 유지하기 용이하다. 카프카(Kafka)와 같은 데이터 스트리밍 파이프라인에서 선호된다. Apache Avro
-
SQLite : SQL이 붙으니 데이터베이스로 착각 할 수 있는데 파일구조이자 라이브러리이다. SQL 과 DB 드라이버를 통해서 DBMS 를 이용하듯이 쓸 수 있다. 임베디드 환경, 단독 프로그램 환경에서 DBMS 사용하듯 데이터를 다룰 수 있어 인기있다.
2.2.2 분석 최적화 컬럼형 형식 (Columnar Formats)
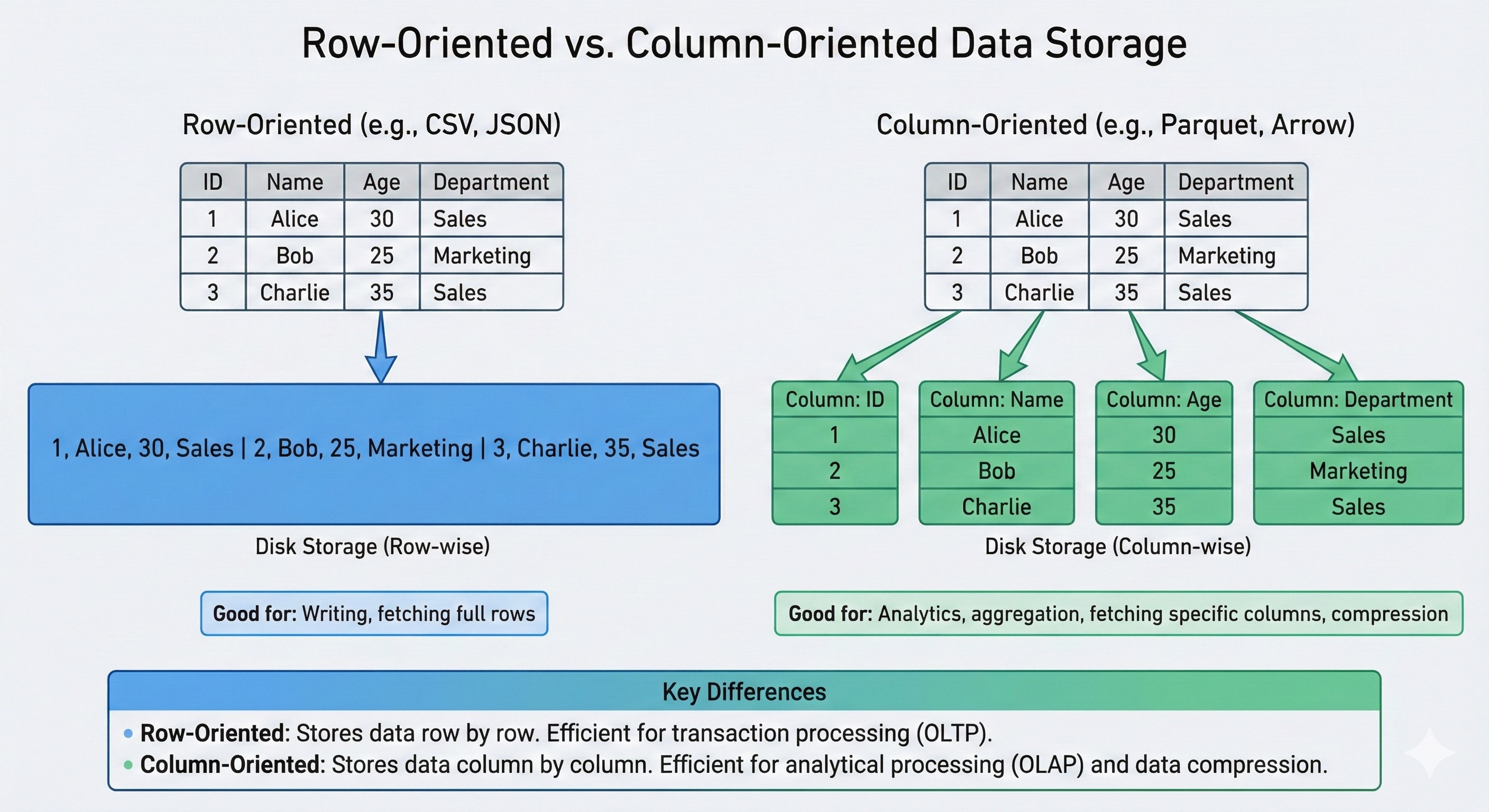
전통적인 행(Row) 기반 저장 방식은 한 레코드의 모든 필드를 연속적으로 저장하지만, 분석 작업은 특정 필드(예: 모든 사용자의 ‘나이’ 평균)만 읽는 경우가 많다. 컬럼형 형식은 동일한 형식의 데이터를 모아서 저장함으로써 I/O를 획기적으로 줄인다. 이러한 데이터구조를 이용한 컬럼나 데이터베이스도 존재한다. 설명만으로는 선듯 이해하기 어려울 수 있는데 실제 사용 사례를 보면 이해 할 수 있을 것이다.
-
Apache Parquet: 하둡 생태계의 표준 컬럼형 저장 포맷이다. 컬럼별로 데이터를 저장하므로 동일한 타입의 데이터가 모여 있어 압축 효율이 매우 높다(RLE, Dictionary Encoding 등 적용). 스파크(Spark), 임팔라(Impala) 등 빅데이터 분석 엔진에서 ‘한 번 쓰고 여러 번 읽는(Write Once, Read Many)’ 워크로드에 최적화되어 있다.
-
Apache ORC (Optimized Row Columnar): 하이브(Hive) 생태계에서 시작된 컬럼형 포맷으로, Parquet와 유사한 목표를 가지지만 하이브의 ACID 트랜잭션 지원 등에 더 특화되어 있다. 인덱싱 기능이 내장되어 있어 특정 범위의 데이터를 건너뛰는(Predicate Pushdown) 성능이 우수하다.
-
Apache Arrow: 디스크 저장이 아닌 인메모리(In-Memory) 분석을 위한 컬럼형 포맷이다. CPU와 GPU가 데이터를 효율적으로 처리할 수 있도록 메모리 레이아웃을 표준화하였다. 이를 통해 서로 다른 시스템(예: Python Pandas와 Spark) 간에 데이터를 직렬화/역직렬화 없이(Zero-Copy) 공유할 수 있게 하여 분석 속도를 극대화한다. 메모리에 로딩해서 다루는 특징 때문에 RDMA(Remote Direct Memory Access) 가 가능해서 빅데이터, AI 에서 특히 각광받고 있다.
2.3 과학 및 특수 목적 파일 형식
과학, 의료, 엔지니어링 분야에서는 다차원 배열이나 메타데이터를 효율적으로 처리하기 위한 특화된 형식이 사용된다.
이러한 파일 포맷들은 서버 프로그램에서 파일을 직접 다룰 때, 성능을 극대화하기 위해 고안되었다.
-
HDF5 (Hierarchical Data Format v5): 대용량의 과학 데이터를 저장하기 위한 파일 형식이다. 파일 내부에 디렉토리 구조(Group)와 데이터셋(Dataset)을 가질 수 있어 '파일 속의 파일 시스템’처럼 작동한다. 기상청, NASA 등에서 위성 데이터나 시뮬레이션 결과를 저장하는 데 사용된다.
-
NetCDF (Network Common Data Form): HDF5를 기반으로 하여 지구과학 데이터 공유를 위해 개발된 형식이다. 배열 지향적 데이터 접근을 지원하며, 기후 모델링 등의 분야에서 표준으로 쓰인다.
-
DICOM (Digital Imaging and Communications in Medicine): 의료 영상의 국제 표준이다. MRI, CT 등의 이미지 데이터뿐만 아니라 환자 정보, 촬영 장비 정보 등의 메타데이터를 하나의 파일에 통합하여 저장한다. 이는 의료 데이터의 무결성을 보장하는 데 중요하다.
-
NIfTI & FITS: NIfTI는 신경과학 분야(fMRI 등)에서 사용되며, FITS는 천문학 분야에서 천체 이미지와 관측 데이터를 저장하는 데 사용되는 표준 형식이다.
3. 압축 기술
데이터의 이동 속도는 레지스터 - 램 - 디스크 - 네트워크 순으로 느리다.
물론 Infiniband 처럼 HDD 보다 빠른 네트워크도 있다.
일반 사용자 인터넷 환경으로 한정해보자.
사용자에게 데이터를 전송하는데 압축을 해서 전송량을 줄이는 것이 최종적으로 더 빠를 수 있다.
그리고 인터넷 트래픽은 비용이 발생하므로 인터넷 전송에서는 압축이 필수이다.
압축 효율과 압축 속도는 반비례 하므로 용도에 따라 다르게 적절한 알고리즘을 선택해야 한다.
3.1 무손실 압축 (Lossless Compression)
원본 데이터를 비트 단위까지 완벽하게 복원할 수 있는 압축 방식이다. 텍스트, 소스 코드, 데이터베이스 파일 등에 사용된다.
3.1.1 기본 원리 및 알고리즘
-
LZ77 / LZ78: 슬라이딩 윈도우를 사용하여 이전에 나온 문자열을 참조로 대체하는 딕셔너리 기반 알고리즘의 시초이다.
-
Huffman Coding: 빈도가 높은 문자에 짧은 비트를, 빈도가 낮은 문자에 긴 비트를 할당하는 엔트로피 인코딩 방식이다.
-
DEFLATE: LZ77과 Huffman Coding을 결합한 알고리즘으로, ZIP, Gzip, PNG 등에서 사용되는 가장 보편적인 압축 기술이다.
3.1.2 고압축률 알고리즘 (Archival)
-
LZMA (Lempel-Ziv-Markov chain algorithm): 7-Zip (.7z)과 .xz 형식에서 사용된다. 거대한 딕셔너리 크기(수 GB)와 범위 부호화(Range Coding)를 사용하여 압축률을 극대화한다. 압축 속도는 느리고 메모리를 많이 소모하지만, 배포용 파일 압축에 이상적이다.
-
RAR: 독점적인 알고리즘을 사용하는 압축 포맷으로, 멀티미디어 압축과 오류 복구 기능이 강력하다.
-
LZA: 일부 문헌이나 파일 확장자(.lza)에서 발견되는 이 형식은 Lempel-Ziv-Oberhumer(LZO) 알고리즘 기반의 애니메이션 포맷을 지칭하거나, 특정 압축 유틸리티의 확장자로 쓰이는 틈새 포맷이다. 일반적인 맥락에서는 LZO나 LZMA 계열 기술의 변형으로 이해할 수 있다.
-
Zstd (Zstandard): 페이스북이 개발한 알고리즘으로, LZ4에 버금가는 속도와 높은 압축률을 동시에 제공하여 최근 리눅스 커널과 데이터 시스템에서 새로운 표준으로 자리 잡고 있다고 하는데, 저는 접해보지 못했습니다.
3.1.3 고속 압축 알고리즘 (Real-Time)
-
LZ4: 압축률보다는 압축 및 해제 '속도’에 최적화된 알고리즘이다. 코어당 수백 MB/s의 처리 속도를 보여주며, ZFS 파일 시스템, 데이터베이스 페이지 압축, RAM 압축 등에 필수적으로 사용된다.
-
Snappy: 구글이 개발한 알고리즘으로, 적당한 압축률과 매우 빠른 속도를 목표로 한다. 빅데이터 시스템(Hadoop, HBase) 내부의 데이터 전송 압축에 많이 쓰인다.
-
LZO: 압축 해제 속도가 매우 빠른 알고리즘으로, 임베디드 시스템이나 리눅스 커널 압축 등에 사용되어 왔다.
3.1.4 차세대 균형 알고리즘
-
Zstandard (Zstd): 페이스북이 개발한 알고리즘으로, DEFLATE와 유사한 압축률을 보이면서 속도는 훨씬 빠르거나, LZMA에 근접한 압축률을 제공하면서도 실용적인 속도를 유지하는 등 유연성이 매우 뛰어나다. 현대 리눅스 커널과 데이터 시스템의 새로운 표준으로 자리 잡고 있다.
-
Brotli: 구글이 웹 전송을 위해 개발했다. HTML, JS 등에 자주 쓰이는 단어 사전을 내장하여 텍스트 압축 효율이 매우 높다.
3.2 손실 압축 (Lossy Compression)
사람의 인지 능력 한계를 이용하여 불필요한 데이터를 제거함으로써 압축률을 높인다.
이미지:
-
JPEG: 이산 코사인 변환(DCT)을 사용하여 고주파 색상 정보를 제거한다.
-
WebP: 구글이 개발한 형식으로, JPEG보다 약 30% 더 작은 크기로 동일한 품질을 제공한다.
오디오:
- MP3, AAC: 청각 심리학적 모델을 이용하여 들리지 않는 소리를 제거한다.
아카이빙(Archiving)과 압축의 차이: Tar는 압축 도구가 아니라 여러 파일을 하나로 묶는 아카이버(Archiver)이다. 리눅스에서는 보통 Tar로 묶은 후 Gzip으로 압축하여 .tar.gz 형태로 사용한다.
3.3 어떤 것을 선택해야 할까?
손실 vs 비손실 , 압축 효율 vs 실시간
DB 내부나 네트워크 전송 시에는 CPU를 적게 쓰면서 압축/해제 속도가 빠른 알고리즘 사용한다. zfs 에서 LZ4를 선택한 것은 압축 효율보다는 실시간성에 방점을 찍었기 때문이다.
백업 파일이나 배포용 파일은 압축률이 높은 방식 사용한다. LZMA (.7z,.xz), Zstd (Zstandard)
http 는 텍스트 문서인 HTML 을 주고 받고, gzip 을 이용한 압축을 지원하여 네트워크 전송량을 줄이고 전송 속도를 빠르게 한다.
4. 파일 시스템
파일 시스템은 OS에서 파일을 안정적이고 효율적으로 관리하기 위해 정의한 것이다.
4.1 파일 시스템의 핵심 개념
-
Inode) (이노드): 파일의 신분증이자 메타데이터 저장소이다. 리눅스/유닉스 계열 파일 시스템은 파일의 실제 이름과 '파일의 정보’를 분리해서 관리한다. Inode에는 파일의 소유자, 권한, 크기, 생성 시간, 그리고 데이터가 저장된 디스크상의 위치(주소)가 담겨 있고, 파일 내용은 데이터 블록에, 파일에 대한 정보는 Inode에 저장되는 구조이다.
-
POSIX (Portable Operating System Interface): 파일 시스템의 표준 인터페이스(약속)이다. 서로 다른 파일 시스템(ext4, XFS, NTFS 등)을 사용하더라도, 응용 프로그램이 파일을 읽고 쓰는 방식(open, read, write)은 동일해야 한다. POSIX 표준을 준수하는 파일 시스템은 OS 입장에서 일관된 방식으로 제어할 수 있어 이식성이 보장된다. 쉽게 말해, 개발자가 파일 시스템 종류를 몰라도 코드를 짤 수 있게 해주는 추상화 계층이다. 덕분에 개발자는 디스크에 저장된 일반 파일뿐만 아니라, 네트워크 소켓이나 파이프 같은 다양한 데이터 스트림도 마치 '파일’인 것처럼 동일한 방식으로 다룰 수 있게 된다. 이는 '모든 것은 파일이다’라는 유닉스 철학의 기반이 되며, 물리적 저장소의 파일뿐 아니라 소켓, 파이프 등 다양한 입출력 대상을 동일한 추상 계층에서 제어할 수 있게 해준다. 서버를 운영하다보면 "can’t open file descriptor"라는 문구를 만날 수 있는데 이것 또한 "파일"뿐 아니라 “소켓” 누수 때문에 발생 할 수 있는 일이다.
4.2 리눅스 서버 파일 시스템
-
ext4: 리눅스의 표준 파일 시스템으로 안정성이 뛰어나다.
-
XFS: 대용량 파일 처리와 병렬 I/O 성능이 좋아 RHEL(Red Hat) 계열 등 엔터프라이즈 서버에서 기본으로 사용합니다.
-
ZFS: 데이터 무결성 체크섬, 스냅샷, 압축 기능을 자체 내장하여 “데이터가 절대 깨지지 않아야 하는” 스토리지 서버에 사용됩니다. 캐쉬 때문에 메모리가 많이 필요하며, 압축 기능을 내재하여 CPU 사용량도 높은 편이다. 고성능 시스템일 수록 이득을 보는 파일 시스템이다.
4.3 개인용/데스크톱 파일 시스템 (Windows & macOS)
소비자 입장에서 사용하는 데스크탑 파일 시스템
- FAT32 / exFAT: 구조가 단순하여 Windows, macOS, 리눅스, 게임기 등 거의 모든 장치에서 읽고 쓰기가 가능하다. USB 메모리나 SD 카드에 주로 사용되지만, 파일 권한 관리나 저널링 같은 고급 기능이 빠져 있어 OS 구동용으로는 부적합하다. 또한 FAT32는 4GB 이상 파일 저장 불가하여, 동영상을 저장 할 때 2G 로 분할해서 저장하는 것을 본 분도 있을 것이다. FAT32는 오래된 시스템으로 파일 길이의 제한도 있고, 메타데이터 관리도 불안정 했기 때문에 특수 목적 아니라면 추천하지 않는다.
NTFS: Windows의 현대적인 표준 파일 시스템이다. 저널링(Journaling)을 통해 갑작스러운 종료 시 데이터 복구 능력이 뛰어나며, ACL(접근 제어 목록)을 통한 정교한 파일 권한 관리와 압축, 암호를 지원한다. 안정적이지만 타 OS(macOS 등)에서는 라이센스 문제로 기본적으로 '읽기 전용’인 경우가 많다. Mac 에서 쓰기 가능하게 하는 프로그램도 있긴한데 안정성에 문제가 있던 경험이 있다. OS에 맞는 파일 시스템을 선택하고, 이기종간에는 네트워크를 통해 전송하는게 낫다.
APFS (Apple File System): macOS와 iOS를 위한 최신 표준이다. 플래시 메모리(SSD)에 최적화되어 속도가 매우 빠르며, COW(Copy-on-Write) 기술 덕분에 파일 복제 시 실제 데이터를 복사하지 않고 포인터만 생성하여 순식간에 복사가 완료되며, 강력한 암호화가 지원이 특징이다.
4.4 분산/클라우드 파일 시스템
-
Object Storage : 클라우드 환경의 데이터 저장소 표준이다. 파일 시스템처럼 계층 구조가 아닌 객체(Object) 단위로 관리하며 무한한 확장이 가능합니다. 최신 데이터 레이크하우스 아키텍처의 기반이 된다. 다시 풀어쓰면 일반적으로 디스크와 디렉토리로 파일 관리를 한다. 그러나 대규모 분산 서버 환경에서는 하나의 물리 서버나 디스크만 볼 수 없기 때문에, 여러 서버를 엮어서 사용자는 파일의 URI 만 알면 되고, 어떤 서버의 디스크에 저장되는 지는 Object Storage 시스템에서 관리한다.
대표적으로 AWS S3, Cloudflare R2, Microsoft Azure Blob Storage, Rackspace Cloud Files ,Google Cloud Storage 등이 있다. -
HDFS: 하둡 생태계의 저장소로, 대용량 파일을 블록 단위로 쪼개 여러 서버에 분산 저장한다.
-
JuiceFS: 클라우드 시대에 맞춰 S3와 같은 객체 스토리지를 백엔드로 사용하면서, 고성능 POSIX 파일 시스템 인터페이스를 제공한다.
-
Ceph : 서버들의 하드디스크를 묶어서 하나의 거대한 스토리지 풀로 만듭니다. 그 위에서 블록(RBD), 객체(RGW), 파일(CephFS)을 모두 제공한다.
클라우드 환경에서 Object Storage 를 처음 사용하면 각 서비스 제공자의 라이브러리를 이용하게 될 것이다. JuiceFS, Ceph 등 직접 구축하는건 백엔드 개발보다는 인프라 영역에 가까운 것 같다.
5. DBMS - Database Management System
데이터베이스는 데이터를 체계적으로 저장, 관리, 검색하는 시스템이다. 백엔드 개발을 처음 시작하면 MariaDB(MySQL), PostgreSQL 등의 관계형 데이터베이스를 접하게 될 것이다. 현대의 DBMS는 전통적인 관계형 모델을 넘어 데이터의 형태와 요구사항에 따라 다양하게 분화되었다.
5.1 관계형 데이터베이스 (RDBMS & ORDBMS)
1970년대 E.F. Codd의 관계형 모델에 기초한 RDBMS는 데이터를 테이블(Table) 형태로 저장하고, SQL을 통해 조작하며, 트랜잭션의 ACID(원자성, 일관성, 고립성, 지속성)를 보장한다. 이 말은 데이터의 정합성을 보장하는 기능을 제공한다는 것이다. 테이블과 컬럼 사이의 관계와 제약사항을 정의하고 데이터 조작 시 제약사항을 만족시키는지 감시한다.
데이터의 주인(Primary Citizen)이 테이블이냐, 객체냐에 따라 OODBMS, ORDBMS로 분류 할 수 있다.
-
ORDBMS (Object-Relational DBMS)의 정체성은 “나는 RDBMS다. 그런데 이제 객체도 흉내 낼 수 있다.” 할 수 있다. 여전히 테이블과 행이 기본이다. 기존 RDBMS의 한계를 극복하기 위해 컬럼(객체, 배열, JSON)을 사용자 정의 타입을 넣을 수 있게 확장했다.
-
OODBMS (Object-Oriented DBMS)는 객체 지향 프로그래밍의 객체를 그대로 데이터베이스에 저장하는 방식이다. ObjectDB나 Objectivity 등이 있으며, 복잡한 객체 관계를 매핑 없이 저장할 수 있으나 RDBMS에 밀려 틈새 시장(CAD/CAM 등)에서 주로 사용된다. 구조적 프로래밍 패러다임©에서 객체지향형 프로그램 패러다임(C++)으로 프로그래밍 패러다임의 메인스트림이 바뀔 때 객체지향형 프로그램과 RDBMS의 변환 과정을 간소화 하기 위해 등장한 것 으로 생각한다. 참고 : [임피던스 불일치 Impedance Mismatch] (https://en.wikipedia.org/wiki/Object–relational_impedance_mismatch)
현재는 DBMS라고 하면 일반적으로 RDBMS(관계형 DBMS) 이다. 그리고 순수 OODBMS 는 잘 사용되지 않고, ORDBMS 가 주류를 이루게 되었다. 그리고 대부분의 RDBMS가 ORDBMS 이므로 DBMS = RDBMS = ORDBMS 로 불리고 있는게 현실이다. 학술적으로 엄격히 구분할 때 외에는 구분해서 말하지 않는다.
5.1.1 엔터프라이즈 리더:
-
Oracle Database: 강력한 기능과 안정성, 그리고 다중 버전 동시성 제어(MVCC)를 통해 대규모 엔터프라이즈 환경에서 가장 널리 사용된다.
-
Microsoft SQL Server: 윈도우 생태계와 긴밀하게 통합되어 있으며, 강력한 관리 도구와 비즈니스 인텔리전스 기능을 제공한다.
-
IBM Db2: 메인프레임 시절부터 이어져 온 안정성을 바탕으로 하이브리드 워크로드 처리에 강점을 보인다.
-
Vetica : 버티카는 고속의 SQL 기반 분석 전용 DBMS으로 데이터 웨어하우스(DW)와 데이터 레이크를 통합하는 레이크하우스(Lakehouse) 아키텍처를 지원하며, 다양한 데이터 소스(Kafka, S3 등)와 연동 가능하다.
5.1.2 오픈 소스 강자:
-
PostgreSQL: 객체-관계형 데이터베이스(ORDBMS)로 분류된다. 사용자 정의 타입, 상속 등 객체 지향적 기능을 지원하며, PostGIS와 같은 강력한 확장성과 표준 준수율로 인해 현대적인 애플리케이션의 기본 데이터 저장소로 각광받고 있다. 다양한 확장 엔진이 존재하여 인기가 상승하고 있다.
-
MySQL / MariaDB: 웹 애플리케이션에서 가장 널리 쓰이는 RDBMS이다. 읽기 성능이 뛰어나고 구조가 단순하다. 오라클의 인수 이후, 그 창시자들이 포크(Fork)하여 만든 MariaDB가 오픈 소스 정신을 계승하고 있다.
- 사족 : 2천년대 초반쯤에 오픈소스 무료 DBMS로 MySQL이 절대 강자였다. 그러나 DBMS 책들은 오라클이나 DB2가 주류였고, 각 DBMS마다 표준 SQL 이 아닌 고유의 문법이 있다. MySQL은 표준 SQL 을 전체 구현하지 않았어서 책을 보고 실습하면 안되는것이 많았다. MySQL 로 시작해서 PostgreSQL 로 넘어갔는데 MySQL 에서 안되는게 PostgreSQL에서는 잘 된 경험이 기억난다.(구체적인 기억은 잘 안난다) 그래서 PostgreSQL 사용 후에는 계속 PostgreSQL 만 찾게 되었다.
- DBA(DBMS Administrator) : 처음에는 SQL을 이용해 데이터 다루는 것을 경험 할 것인데, 실제 서비스에 이용하면 각 DBMS 의 특징을 잘 알아야 한다. 유지보수와 성능을 위해 알아야 하는 사항이 있고, DBMS 마다 지원 기능과 성능 향상을 위해 알아야 하는 사항이 다르다. 따라서 DBA는 DBMS 에 관한 전문가로써 데이터 규모가 커질 수록 꼭 필요한 역할이다.
5.2 NoSQL (Not Only SQL)
2000년대 후반, 웹 스케일의 데이터 처리와 비정형 데이터의 증가로 인해 등장하였다. 스키마 유연성과 수평적 확장성(Scale-out)을 위해 ACID 속성을 일부 완화(BASE 모델)하기도 한다. 전통적인 테이블 기반의 아키텍처가 아닌 시스템을 칭하지만 일반적으로 NoSQL 이라면 문서지향(Document Stores) 로 통용된다.
5.2.1 문서 지향 (Document Stores)
JSON이나 XML과 같은 문서 형태로 데이터를 저장한다. 스키마가 고정되어 있지 않아 개발 유연성이 높다.
-
MongoDB: 가장 대표적인 문서형 DB로, BSON 포맷을 사용한다. 샤딩(Sharding)을 통한 확장이 용이하며, 풍부한 쿼리 기능을 제공한다.
-
CouchDB: HTTP 프로토콜과 JSON을 사용하여 웹 친화적이며, 멀티 마스터 복제 기능을 통해 오프라인 동기화 시나리오에 강력하다.
-
Amazon DynamoDB: 완전 관리형 서비스로, 키-값 및 문서 모델을 모두 지원하며 규모에 관계없이 일관된 성능을 보장한다.
5.2.2 키-값 저장소 (Key-Value Stores)
가장 단순한 데이터 모델로, 고유 키에 값을 매핑하여 저장한다. 메모리에 데이터를 유지하므로 속도가 매우 빠르다. 최저 레이턴시를 제공하기 위한 전략들이 상이하며 메모리에 데이터를 저장하므로 프로그램 재시작 시 데이터가 상실된다. 그러나 최근에는 디스크에도 데이터를 유지하도록 하여 영속성을 보장하는 기능을 제공하기도 한다. 이런 프로그램은 엄격히 말하면 DBMS 라고 하지는 않지만 자주 사용되므로 소개한다.
-
Redis: 인메모리 기반의 데이터 구조 저장소이다. 단순한 문자열 외에도 리스트, 셋, 해시 등 다양한 자료구조를 지원하며, 캐시나 메시지 브로커로도 사용된다.
-
Memcached: 고성능 분산 메모리 객체 캐싱 시스템이다. 멀티스레드 아키텍처를 가지며 단순한 캐싱 용도로 널리 쓰인다.
-
Riak: 분산 시스템의 가용성을 최우선으로 설계된 키-값 저장소로, 아마존의 다이나모(Dynamo) 논문을 구현하였다.
-
Valkey : 라이센스 문제로 시끄러웠던 Redis를 대체하기 위해 등장한 오픈소스 키-값 저장소이다.
5.2.3 컬럼 패밀리 (Wide-Column Stores)
구글의 BigTable 논문에서 파생된 모델로, 대량의 데이터를 컬럼 단위로 묶어서 분산 저장한다.
-
Apache Cassandra: 쓰기 성능과 가용성이 뛰어난 분산 DB이다. 단일 실패 지점이 없는 링 아키텍처를 가지며, 시계열 데이터나 IoT 로그 처리에 적합하다.
-
HBase: 하둡 파일 시스템(HDFS) 위에서 동작하는 분산 DB로, 대규모 데이터에 대한 무작위 읽기/쓰기를 지원한다. 강력한 일관성(Strong Consistency)을 보장한다.
-
ScyllaDB: 카산드라를 C++로 재작성하여 성능을 극대화한 DB이다. 샤드-퍼-코어(Shard-per-core) 아키텍처를 통해 낮은 지연 시간을 제공한다. NoSQL 이기도 하다. 고유의 캐시 기능을 통해서 Redis 등 캐쉬 프로그램을 대체할 수 있다는 주장도 하고 있다.SyllaDB-Cache 컬럼나 특성상 시계열 데이터, 로그 처리 등에 적합하며, NoSQL 이라서 다른 Document DB 를 대체 할 수 있다고 한다.
-
MariaDB, PostgreSQL : 확장 엔진으로 컬럼 기반 데이터 스토어를 제공한다.
5.2.4 그래프 데이터베이스 (Graph Databases)
데이터 간의 관계(Relationship)를 1급 시민으로 취급하여, 복잡한 연결망을 탐색하는 데 최적화되어 있다.
속성 그래프 (Property Graphs): 노드와 엣지에 속성(Key-Value)을 저장할 수 있는 모델이다.
-
Neo4j: 가장 대중적인 그래프 DB로, 인덱스 없이 노드 간 포인터를 따라가는 '인덱스 프리 인접성’을 통해 빠른 탐색 속도를 제공한다.
-
JanusGraph: 분산 그래프 DB로, 스토리지 백엔드로 Cassandra나 HBase를 사용한다.
-
RDF 트리플 저장소 (RDF Triple Stores): 시맨틱 웹 표준인 주어-술어-목적어(Triple) 구조를 사용한다.
-
AllegroGraph, MarkLogic: 추론(Inference) 기능과 복잡한 메타데이터 관계 분석에 강점을 가진다.
위에 소개된 분류에 따라 제품들을 언급했지만 하나의 프로그램에서 다양한 형태의 기능과 양상을 제공해서 NoSQL 이면서 컬럼나이고, RDBMS이면서 시계열DB일 수도 있고 하다. 분류에 너무 집착하지 않아도 된다.
5.3 NewSQL 및 분산 SQL
NoSQL의 확장성과 RDBMS의 트랜잭션(ACID) 보장을 동시에 달성하려는 시도이다. 특히, 분산환경에서 확장에 신경 쓴 것이다. 분산환경은 부분 장애에도 취약하므로 CAP 정리 CAP Theorem 에 따른 문제를 극복하기 위해 서로 다른 방안을 채택하므로 시스템이 추구하는 목적이 무엇인지 정의하고 DBMS를 선택해야 한다.
-
Google Spanner: 원자 시계(TrueTime)를 사용하여 전 세계에 분산된 노드 간의 일관성을 보장하는 선구적인 시스템이다. (그런데 원자 시계가 필요하다고!!?)
-
CockroachDB: 스패너의 아키텍처를 오픈 소스로 구현한 것으로, 강력한 생존성을 목표로 한다. 디스크, 서버, 랙, 데이터센터 장애에도 데이터 무결성을 유지한다. 수평 확장, PostgreSQL 호환, Serializable 트랜잭션이 특징이다. 데이터를 여러 서버에 분산해서 저장하고, 일관성 유지를 위해 Raft consensus 알고리즘을 사용한다.
-
TiDB: MySQL과 호환되는 분산 DB로, 연산과 저장을 분리하여 유연한 확장을 지원한다.
-
VoltDB: 인메모리 기반의 고속 트랜잭션 처리 시스템으로, 통신사 등 초저지연이 필요한 분야에서 사용된다.
-
YugabyteDB: PostgreSQL 호환성을 제공하는 고성능 분산 SQL DB이다.
5.4 임베디드 데이터베이스 (Embedded Databases)
애플리케이션 내부에 라이브러리 형태로 포함되어 별도의 서버 프로세스 없이 동작하는 DB이다.
-
SQLite: 전 세계에서 가장 많이 배포된 DB 엔진이다. 서버 없이 단일 파일에 데이터를 저장하며, 모바일 앱, 브라우저, 임베디드 기기의 표준 저장소이다.
-
DuckDB: "분석을 위한 SQLite"라 불린다. 로컬 파일(CSV, Parquet)에 대해 고성능 분석 쿼리(OLAP)를 수행할 수 있는 임베디드 DB이다. DB라기보다는 분석 라이브러리에 가까운것 같다.
-
RocksDB & LevelDB: 구글(LevelDB)과 페이스북(RocksDB)이 개발한 키-값 저장소 라이브러리이다. LSM-Tree(Log Structured Merge Tree) 구조를 사용하여 쓰기 성능이 매우 뛰어나며, 많은 분산 DB(CockroachDB 등)의 스토리지 엔진으로 사용된다.
-
Realm: 모바일 환경에 최적화된 객체 데이터베이스로, SQLite보다 빠른 속도와 직관적인 객체 매핑을 제공한다.
5.5 특수 목적 데이터베이스 엔진
5.5.1 시계열 데이터베이스 (Time-Series Databases)
시간의 흐름에 따라 발생하는 데이터(로그, 센서 데이터, 주가 등)를 처리하는 데 최적화되어 있다. 시계열 데이터의 특징은 대상과 시간이 데이터를 조회하는 기준이 된다는 것이다. 이것은 컬럼 기반 데이터처리와 매우 유사하다. 또한 데이터가 시간에 따라 발생하므로 데이터가 기록 될 때 마지막 데이터보다 더 일찍 발생한 데이터가 추가되지는 않는다.(하지만 장애 상황 등에 따라 데이터를 채워야 하는 경우는 있을 수 있다) 그리고 데이터 분석을 위해서는 Raw 데이터 보다 통계 기법을 이용해 특정 주기의 데이터를 생성해서 분석하는게 나은 경우도 있다. 이러한 특징들을 만족시키기 위해 각자 다른 방식을 채택했다.
-
InfluxDB: 가장 널리 쓰이는 오픈 소스 시계열 DB로, 전용 쿼리 언어를 제공하며 고속 쓰기와 압축에 강하다.
-
TimescaleDB: PostgreSQL을 확장하여 만든 시계열 DB로, 표준 SQL을 그대로 사용하면서 시계열 데이터의 파티셔닝(Hypertables)을 자동화한다. 현재는 TigerData 로 이름을 바꾸고 AI 에 적합한 기능을 추가하고 있다.
-
Kdb+: 금융권의 초고빈도 매매(HFT) 시스템에서 사실상의 표준으로 쓰이는 고성능 DB이다.
5.5.2 벡터 데이터베이스 (Vector Databases)
AI 모델이 생성한 임베딩(Embedding) 벡터를 저장하고 유사도 검색(Nearest Neighbor Search)을 수행한다. 벡터는 실수 배열이다.
-
Pinecone, Milvus, Weaviate: 벡터 검색에 특화된 전용 DB들로, HNSW 알고리즘 등을 사용하여 수십억 개의 벡터 중에서 유사한 항목을 밀리초 단위로 찾아낸다.
-
Chroma: 개발 편의성을 강조한 AI 네이티브 임베딩 DB이다.
5.5.3 공간 데이터베이스 (Spatial Databases)
지리 정보(GIS) 데이터를 저장하고 공간 쿼리를 수행한다. 복잡한 기하학적 연산과 좌표계 변환을 제공하는 것이 특징이다.
-
PostGIS: PostgreSQL의 확장 모듈로, 공간 DB의 표준과도 같다.
-
Oracle Spatial: 오라클 DB의 공간 데이터 처리 기능으로, 엔터프라이즈급 GIS 기능을 제공한다.
5.5.4 검색 엔진 (Search Engines)
텍스트의 역인덱스(Inverted Index)를 생성하여 전문 검색(Full-text Search)을 지원한다. AI 시대에 들어서 전통적인 전문검색에 더해 벡터 저장과 유사도 검색을 제공하여 하이브리드 검색을 제공하는 것이 대세가 되고 있는 것으로 보인다. LLM 모델 이용해 인덱스 하는 것이 통합되는 추세이다.
-
Elasticsearch: 루씬(Lucene) 기반의 분산 검색 및 분석 엔진이다. 로그 분석(ELK 스택)과 애플리케이션 검색 기능 구현에 지배적으로 사용된다.
-
OpenSearch : Elasticsearch 가 라이센스 문제로 AWS 와 마찰이 있어서 아마존이 Fork하여 시작한 프로젝트다. 현재는 리눅스 재단에서 관리한다. 검색엔진 기능은 Elasticsearch 와 크게 다를게 없으나 로그 분석 ELK 스택은 아직 부족해 보인다.
-
Solr: 역시 루씬 기반이며, 전통적인 엔터프라이즈 검색 시장에서 강세를 보인다.
-
Vespa: 야후가 개발한 엔진으로, 검색과 추천 시스템, 그리고 벡터 검색을 실시간으로 통합 처리하는 데 특화되어 있다.